In that fraction of a second after you clicked the button saying “Search,” a spider springs into action, crawling as fast as physically possible to get your information to you in less than a second. That spider is using all eight of its legs at hyper-speed, but you never see it. What exactly are these web crawlers?
Simply put, they are computer programs that are able to process information methodically and rapidly, adding the relevant URLs to a list of sources, called the crawl frontier. Because the task is done quickly each time, it’s easy to assume that this task is easy. However, there are three characteristics of the web that make it great for users, but horrible for computer scientists who are designing these web crawlers.
One is that there the Internet is constantly changing its content, which means that by the time the crawler has downloaded the frontier, there’s a high probability that those pages have been modified or deleted since the crawler analyzed it. Another is that there are constantly new pages being generated, some in other languages, so the web crawler has to sift through those as well. The third reason is that the Internet’s sheer volume of information, and the crawler has to tailor its findings to suit your search.
Despite the odds against it, the spider is not so easily defeated. It has four weapons to aid it in the battle against irrelevancy: selection policy, re-visit policy, politeness policy, and parallel computing policy.
In selection policy, the bot employs one of three methods to find the “seeds,” or the URLs to be displayed on the frontier, and then analyzes each site individually for relevance. An important algorithm named OPIC (On-line Page Importance Computation) shows promise to make current search engines more effective, but it has not been tested yet on the web. Most of the time, using a previous crawl path to direct a current demand is most effective, which is why Google searches of the same thing look the same.
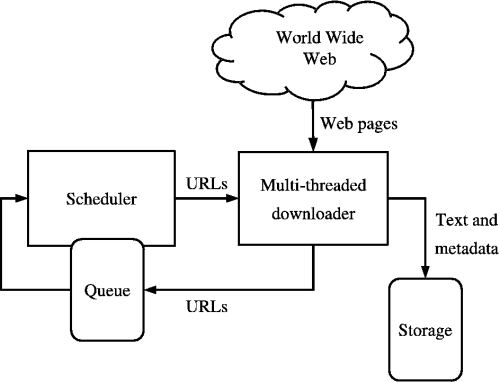
In the re-visit policy, the computer has to first have analyzed the original state of the website for relevancy. By the time another search of the same nature is made, if that site has changed in any way, the website is given a value of 1 in binary code, and it moves up in the selection process. If it has not changed recently, the website is given a value of 0. This keeps the most recently updated information in the front of the frontier, which explains how Wikipedia is usually one of the top results.
The politeness policy actually hinders the ability of a crawler to download information in the short term because it prevents multiple crawlers from retrieving the URL at the same time from one server. The server could crash if it has too many demands at once, so computer scientists have put what is called a “crawl delay” on the time it takes the frontier to develop. These delays range in time from 1 second to 3 minutes, although the latter is highly impractical.
Finally, there is the parallel computing policy, which takes a large problem and breaks it down into smaller bits, which are all solved at the same time. The ultimate problem of this policy is it is possible to have multiple downloads of the same page, so to prevent this the crawler will assign sub-URLs on the frontier space.
There is much more to learn and develop about web crawlers, and it remains an important topic in the field of computer science. If you want more information, feel free to Google it, or use this site or view the page as a Googlebot would:
Happy crawling!